近期,大數據獨角獸Palantir憑借其在國防領域的深度應用引發行業關注,其核心的“本體論”方法論體現了一種追求規范與統一的工程思想。
Palantir的“本體論”方法論為數據應用提供了重要的理論基礎。該方法論強調通過預先定義完整的業務實體、關系與規則,構建統一的數據語義框架,確保數據的準確性與一致性。這種“精密工程”式的approach,在業務邏輯相對穩定、對數據一致性要求極高的場景(如國防、金融風控等)中展現出獨特價值。
數睿數據于2024年發布的「數據通」是基于smardaten構建的面向數據工程的產品解決方案。它與Palantir的核心理念驚人的相似,承襲并通過方法論進化與實踐創新,實現更輕量、更敏捷的本土化實踐。
今天,我們就來做一個詳細的拆解!
一、承襲核心理念 以“模型”理解世界
Palantir 本體論不是簡單的對數據進行抽取、轉換、加載,而是先構建一個能夠精準描述企業業務運作的抽象數據模型。這個模型定義了:
·實體:如客戶、供應商、訂單、設備
·實體之間的關系:如“客戶” “創建了”“訂單”
·實體的屬性:如“客戶”有“名稱”、“ID”、“行業”等屬性
數據通所倡導的“讓數據快速使用”的方法,在理念上與“本體論”不謀而合,并體現在專家知識庫的構建中。同樣是先構建一個抽象的行業模型庫,通過沉淀算法庫、標準庫、字段庫與模型庫,將行業專業知識系統化封裝。數據通用戶手冊中“專家庫的構建方法”相關章節,可以看出其構成要素與Palantir本體論高度對應。
兩者都堅信,有效的數據治理和分析必須始于對業務本身的深刻理解和模型化抽象,而不是始于原始數據的粗暴處理。 這解決了傳統數據治理中“業務含義不清、數據模型設計與物理表開發斷鏈”的根本痛點。
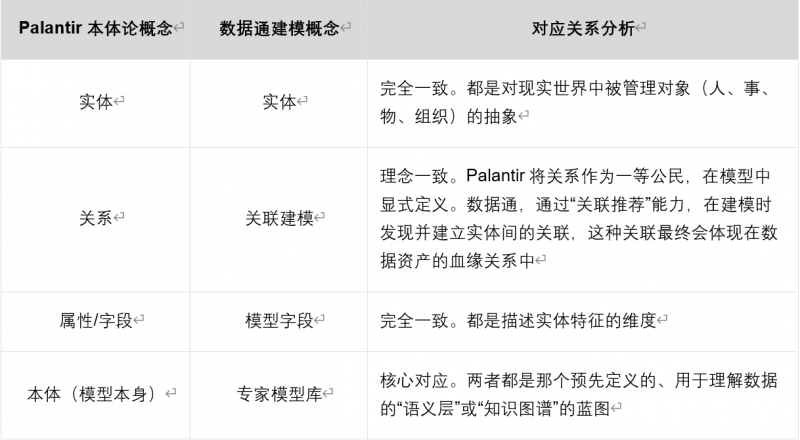
Palantir本體論與數據通建模概念的對應關系
二、進化方法論 從“專家訪談”到“產品化輕量實踐”
1.實體識別方法的智慧
Palantir 的實施通常從與業務專家的大量訪談開始,以提取業務本體。數據通則更非常具體地給出了兩種構建實體的方法,這可以看作是Palantir方法的流程化和工具化:
方式1:圍繞業務場景設計 這類似于Palantir的“逆向工程”,從業務流程(如“客戶下單”)中提取實體(“客戶”、“訂單”)和事件(“下單事件”)。
方式2:圍繞分析場景設計 即從分析目標(如“銷售指標”)反推需要的明細數據(“銷售記錄”)和維度實體(“商品”、“員工”),這是一種更符合數據倉庫建設思維的方法。
這種結合兩種思路的方法,使得數據通既具備了Palantir的業務洞察深度,又兼顧了傳統數據分析的需求,實用性更強。

數據通實體識別方法
2.專家規則——自動化的基石
這是兩者最精彩的交匯點。Palantir 的強大之處在于一旦本體建立,它能自動發現數據源中的實體并與本體映射,實現“快速找數”。數據通的“主動數據治理”理念,其“主動”性就體現在這里:
·專家規則:“映射規則”、“識別規則”(如身份證識別算法),就是Palantir中用于自動化映射的“規則”或“插件”的體現
·AI技術:利用識別算法通過數據內容來判斷字段含義,這比單純依賴元數據匹配更智能,與Palantir使用的技術類似
·復用與沉淀:即實施了一個或多個項目后,轉換算法就會逐步沉淀下來,供后續建模時復用。這正是在構建一個不斷成長的、行業化的“專家知識庫”,這與Palantir在不同項目(如政府、金融、醫療)中積累的行業本體庫思路完全一致
可以說,數據通的“專家知識庫”不僅僅是數據模型的定義,更包含了實現自動化治理的“規則和算法”,這與Palantir本體論驅動的自動化數據集成理念不謀而合。
3.關鍵差異與數睿數據·數據通的特色
盡管理念與方法同源,但兩者仍有一定區別:
·受眾轉變:Palantir更像一個“專家”平臺,由數據科學家和工程師主導,通過代碼進行高級別的本體定義和集成,靈活性強,但門檻高。數據通更偏向“具備數據思維的業務人員”。相較于Palantir的代碼驅動模式,數據通通過可視化建模、自然語言交互等產品化設計,使業務專家也能主導數據模型構建——這正是其“輕量級”實踐的核心體現。數據通產品手冊中有大量詳細工具的使用指引,充分體現了這種“開箱即用”的產品化思路。
·范圍聚焦:Palantir本體論貫穿從數據集成、治理到分析應用的整個鏈條,尤其擅長處理復雜、異構的關系網絡數據。數據通則明確其范圍“以數據模型為基石,向分析應用延伸”,更側重于為數據倉庫/數據中臺的底層建設提供一種先進的、自動化的模型設計方法,是數據治理流程的上游環節。
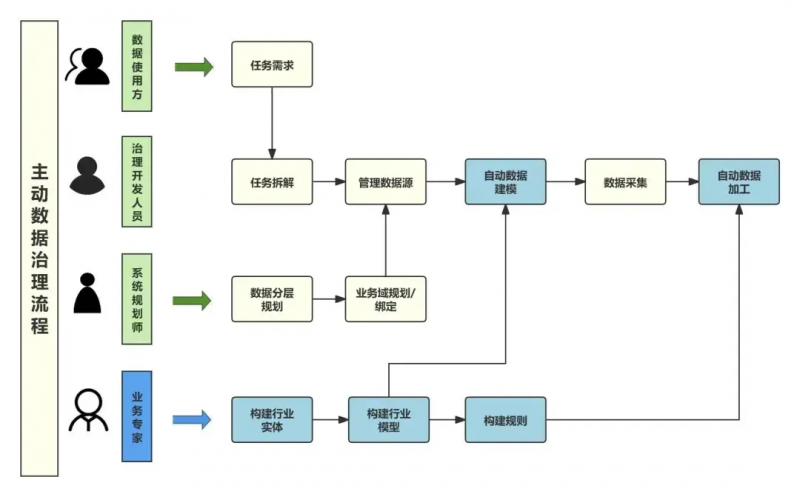
專家知識庫在數據治理中的應用邏輯
三、數睿數據模式創新,漸進式敏捷與智能閉環
1.漸進式敏捷構建:邊用邊建,快速見效
與傳統“大而全”的模型先行不同,數據通倡導從核心場景切入,邊使用邊完善知識庫。
這里面有兩個點值得強調:一是基于數據通自動建模能力,用戶可以提問并不斷追問,在各類分析場景中穿梭,最終達成用戶滿意的問數意圖。二是數據通還會拆解意圖然后告訴你他是怎么分析的邏輯,用戶在過程中也能判斷數據通的分析邏輯和思維鏈是否正確。如果發現數據缺失,他也會告訴你,引導反向補全數據源。
這樣即便在初期數據基礎薄弱的場景之下,依然有較好的可用性。隨著專家知識庫的持續學習和完善,分析的準確性與覆蓋度將快速提升。
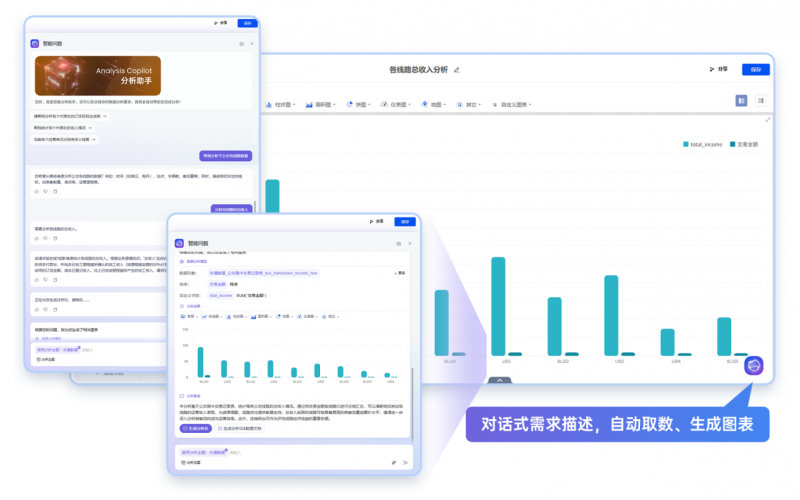
智能問數意圖拆解
這種邊用邊建的優勢也很突出:初始門檻低,無需前期巨大投入,快速啟動并見到一定成效;伴隨業務持續補充。這種模式使得數據通更加適合快速變化的業務環境,如工業制造、數字營銷等行業領域。
2.Data Agent與自然語言理解:智能響應閉環
數據通采用AI智能體和自然語言對話,驅動數據快速使用的過程。這讓用戶的使用和維護都更加簡單。
·Data Agent:實現“智能取數—主動治理—智能問數”全流程閉環,能根據場景動態獲取信息并生成數據分析模型。
·自然語言理解: 徹底降低使用門檻,用戶直接以“分析工廠缺陷率趨勢”等自然語言下達指令,系統精準解析并直接交付結果。
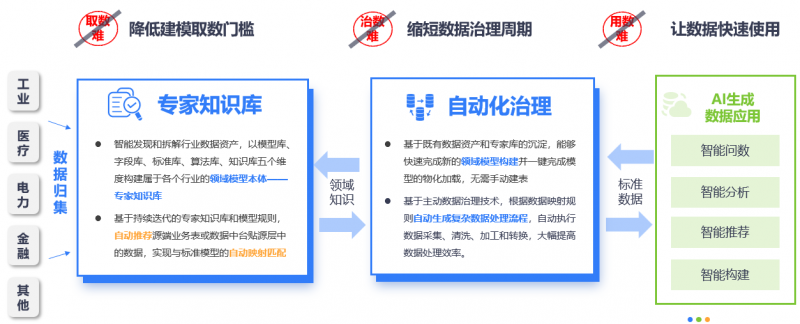
四、實踐印證,數睿數據敏捷響應正在釋放巨大價值
目前在衛健、電力、制造等行業的領先企業已經開始擁抱“敏捷響應”的新模式。
以某市衛健委項目為例,其成功關鍵在于漸進式策略。項目并未在一開始追求構建完美而龐大的數據模型,而是聚焦于“醫療質量監測”等關鍵場景,快速梳理并沉淀了覆蓋診療、藥品、病種等60+項醫療領域數據模型,每個模型統一定義所有數據字段和標準,構建于數據通的專家知識庫中。
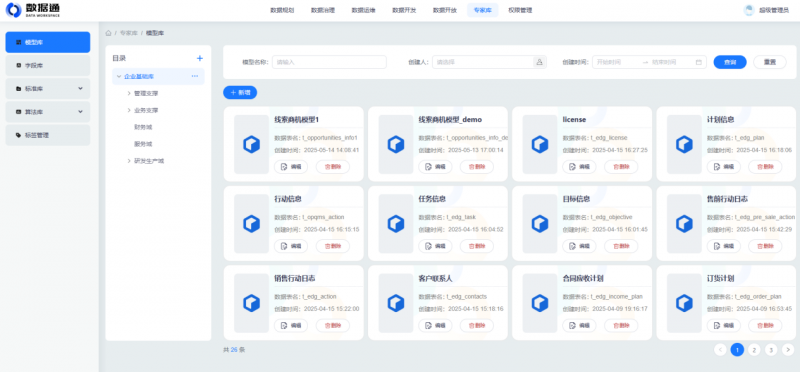
專家知識庫模型在數據通中的配置效果
在此基礎上,數據通逐步開始接入轄區醫院的異構數據源,完成超過20萬張數據表的整合與治理,形成了統一規范的醫療數據中心。依托專家知識庫的支撐,平臺已能夠對部分場景實現自動化映射和智能匹配推薦,從而抽取出目標數據,將跨院數據獲取從被動轉為主動,將原本耗時三個月的人工比對工作,壓縮至短短一周。
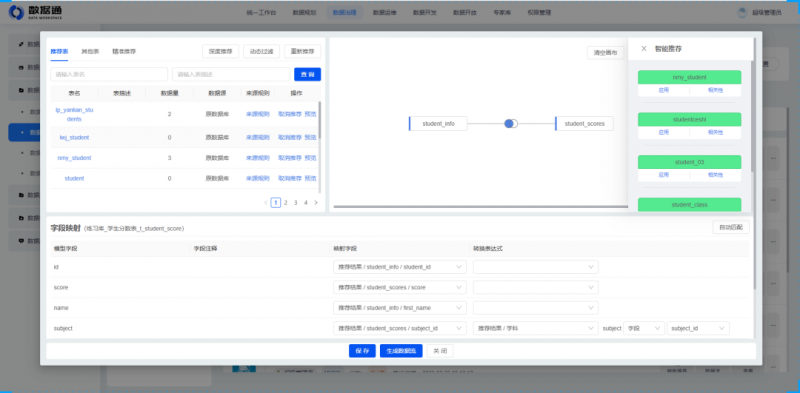
主動數據治理智能匹配推薦
在項目成功上線后,隨著接入醫院數量增加至40個及業務場景的不斷擴展,平臺內沉淀的專家數據模型從初始聚焦核心場景的60余個,逐步豐富至200余個,顯著提升了AI大模型對醫療業務語義的理解能力,智能治理與分析的場景覆蓋面日趨全面。
現在,只需像聊天般輸入需求,曾經需要專業團隊耗時數周完成的"慢性病監測報告"、"就診趨勢分析"、"疾病流行趨勢預測"等復雜任務,如今彈指間就能躍然屏上。這一過程充分體現了“數據越流動越智慧,越使用越增值”的平臺進化價值。
結語
如果Palantir的本體論是構建企業“數據大腦”的尖端哲學,那么數睿數據·數據通就是一套成熟可操作的本土化工程藍圖。它承襲了模型驅動的核心理念,進化出更輕量、產品化的方法論,并通過漸進式敏捷與智能閉環實現了規模化交付。
轉自:千龍網


【版權及免責聲明】凡本網所屬版權作品,轉載時須獲得授權并注明來源“中國產業經濟信息網”,違者本網將保留追究其相關法律責任的權力。凡轉載文章及企業宣傳資訊,僅代表作者個人觀點,不代表本網觀點和立場。版權事宜請聯系:010-65363056。
延伸閱讀



