在 2025 年 11 月 18 日 Cloudflare 全球大規模宕機后,12 月 5 日 Cloudflare 又遭遇了一次大范圍服務中斷,返回“500 內部服務器錯誤”信息,導致全球諸多網站和在線平臺紛紛宕機。
誤判的根源
傳統安全“看得見流量,看不懂行為”
當外部鏈路出現大范圍異常時,企業內部往往會同步出現:超時、失敗率驟升,重試流量激增,各服務指標劇烈波動,以及鏈路長尾放大。傳統安全系統只看到這些“異常表象”,卻無法理解其產生的原因,于是大量誤判隨之而來。
誤判的本質不在于算法弱,而在于系統“無法理解行為”。這主要體現在以下三個方面:
1.缺乏運行時上下文: 規則、流量特征、閾值變化,只能判斷“像不像攻擊”,卻無法判斷“是否真的觸發了攻擊動作”。
2.可觀測性與安全割裂: 指標、日志、Trace 分散在不同平臺,安全系統難以形成統一視角,自然無法回答:“哪條請求 → 觸發了哪段代碼 → 導致了什么動作?”
3.微服務鏈路導致誤判指數級放大: 一個請求跨越 5~10 個服務。缺少任一段上下文,判斷都可能偏差。
全球性故障暴露的核心問題,在于企業缺乏一個能夠穿透復雜依賴、直達問題本質的觀測與響應體系。
構建全域可觀測韌性
從感知到定位的立體防御
全球性故障暴露出的核心問題,在于企業缺乏一個能夠穿透復雜依賴、直達問題本質的觀測與響應體系。聽云通過整合前端、網絡、應用層及安全側的可觀測能力,構建了一套從即時感知、精確定位、到智能決策的完整韌性系統。
01丨快速發現
RUM 是最快的“警報器”
RUM 在這次故障中的核心價值在于零延遲地感知用戶影響,并迅速定性故障。
01 毫秒級錯誤率飆升檢測
RUM 表現:在 11:28 UTC 客戶首次報告 5xx 錯誤時,一個配置良好的 RUM 產品應該已經在全球范圍內觀察到 HTTP 5xx 錯誤率的陡峭飆升。
傳統監控的滯后性:傳統的后端監控可能需要幾分鐘才能確認是全局問題(因為要排除內部網絡抖動或特定服務器負載高),但 RUM 看到的是用戶瀏覽器接收到的最終錯誤,它反映了用戶的真實體驗。
結論:RUM 是最快拉響警報的工具。它能立即將故障提升為 P0 嚴重度。
02 糾正排查方向:不是 DDoS
時間線的挑戰:Cloudflare 工程師花了超過 90 分鐘(11:32–13:05)誤以為是 DDoS 攻擊。
RUM 的貢獻:RUM 可以快速提供請求量與錯誤率的對比數據。
如果是 DDoS,RUM 應該看到 總請求量(或帶寬)暴增,然后由于系統過載導致 5xx 錯誤率上升。
在這次事件中,RUM 看到的是總請求量可能持平或下降(因為請求被 Cloudflare 攔截或直接失敗),但 5xx 錯誤率卻從 0 飆升到極高水平。
結論: RUM 的數據能迅速證明這不是容量問題,而是服務可用性(Availability)問題,從而幫助團隊在 11:32 就糾正排查方向,節省了 90 分鐘的 MTTR。
然而,RUM 存在能力盲區,它無法定位這次故障的根本原因,因為它不具備對內部基礎設施的洞察能力。RUM 只能看到 Cloudflare 邊緣節點返回的 HTTP 響應頭和狀態碼(500/503),看不到 ClickHouse 數據庫的權限變更記錄、內部 Bot Management 系統的特征文件大小,以及 Rust 核心代碼中的 unwrap() 堆棧追蹤。
02丨獨立觀測
聽云Network 當 CDN 宕機客戶的自救從哪里開始?
當你使用全球 CDN、DNS 或云代理服務時,你的業務健康度已經部分掌握在別人手里。當第三方網絡層出問題時,客戶最典型的三大困境是:監控斷層(內部系統正常,用戶訪問超時)、責任不清(廠商說“網絡可達”,用戶卻打不開)、響應滯后(等官方公告才確認)。
01
客戶真正的痛點不是“掛了”
而是“不知道為什么掛了”
當第三方網絡層出問題時,客戶最典型的三大困境是:

這些問題的根源在于:企業缺乏一個“獨立于廠商”的、外部用戶視角的可觀測體系。
02
撥測的核心價值:
幫你看清“你與廠商之間”的那段路
撥測不是替廠商“抓錯”,而是替客戶“還原事實”,當 CDN 或云服務宕機時,聽云 Network 的撥測體系可以幫企業在幾分鐘內回答這四個關鍵問題:

03
解決方案:從“發現”到“行動”的四步閉環
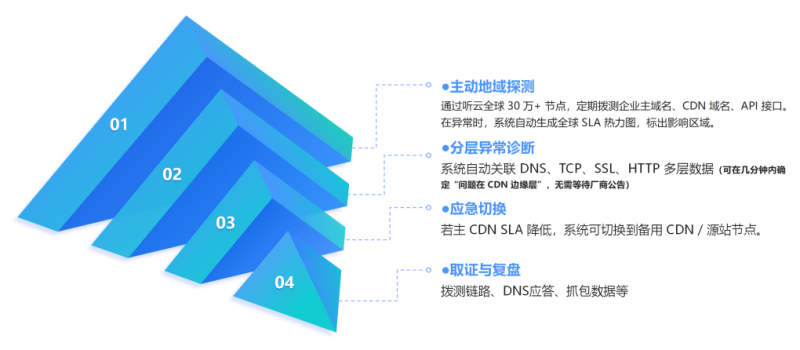
聽云 Network 通過主動地域探測、分層異常診斷、應急切換和取證與復盤,構建了從“發現”到“行動”的四步閉環,幫助客戶建立獨立的觀測韌性。
03丨精準定位
聽云 APM
如何快速定位 Rust 程序的致命崩潰
在這類 Cloudflare 級別的重大故障中,除了誤判風險之外,另一項關鍵挑戰是:如何在 5xx 錯誤爆發時,第一時間定位內部的崩潰根源,而不是誤以為遭遇攻擊。
聽云 APM(應用性能監控)通過“指標 → 鏈路追蹤 → 運行時異常”三段式能力,構建了從現象到根因的完整閉環。
01
指標(Metrics):從 5xx 激增到即時警報
Cloudflare 的事故最早暴露的信號,是核心代理系統(FL/FL2)的 5xx 錯誤數量突然急劇上升。
聽云 APM 的實時指標能力可以:
持續監控核心服務的成功率/錯誤率,在 5xx 數量突破基線時立即觸發警報,明確告訴團隊:“已經不是正常波動,而是系統級故障”。這讓團隊能夠在錯誤首次顯現的第一分鐘,就看到無可爭議的故障信號,避免在早期因 “區域性、偶發性” 而忽略問題。
02
分布式追蹤(Tracing):精準鎖定 Rust 程序崩潰點
當 5xx 警報響起后,關鍵在于快速回答兩個問題:
是否來自外部攻擊?內部鏈路的哪一段崩潰了?
● 指標 (Metrics) 警報 + 消除干擾: 基于 OpenTelemetry Metrics 標準,實時監控 5xx 錯誤 HTTP 狀態代碼數量 的劇增。同時,APM 應具備關聯性分析,如果核心指標異常,且日志未顯示大量外部流量特征,應迅速排除 DDoS 誤判。
● 追蹤 (Tracing) + 異常堆棧鎖定: 利用 OpenTelemetry 分布式追蹤,在 5xx 錯誤鏈路中快速捕獲 Rust 核心代理 的底層崩潰信息(thread fl2_worker_thread panicked: called Result::unwrap() on an Err value)。此信息是內部邏輯錯誤的鐵證,可立即將調查重點從外部攻擊/過載轉向代碼執行和配置數據。
聽云的分布式追蹤會自動記錄每一個請求經過的鏈路:當請求到達 Cloudflare 的核心代理 FL2、代理從 ClickHouse 讀取“特征文件”(Feature File)、文件異常變大 → 觸發讀取失敗、Rust 模塊在執行 unwrap() 后直接 panic。
在鏈路中,這個異常點會被精準標記。
● 鏈路起點:追蹤 Span 的創建與初始化
當用戶的請求在 HTTP/TLS 層終止,并進入核心代理系統(如 FL/FL2)時,基于 OpenTelemetry 標準或 APM 系統的探針必須立即介入,完成以下步驟:
? 啟動追蹤: 為該請求創建一個 主 Span (Root Span)。該 Span 標記了整個請求鏈路的起始點和持續時間,是后續所有操作的計時和上下文載體。
? 上下文初始化: 確保鏈路上下文(TraceID/SpanID)已初始化,并準備好沿著請求流向下游傳播。
● Span 上下文信息的深度注入與富化
當代理系統執行關鍵的外部依賴調用(例如,從 ClickHouse 數據庫集群獲取特征文件)時,必須將以下關鍵的上下文信息注入到當前活動的 Span 中:
? 依賴信息: 數據源標識(如 ClickHouse 查詢的標識或連接串),用于精確匹配和追溯異常的 Clickhouse。
? 系統配置: 當前設定的資源限制(例如,連接池配置),用于區分是代碼錯誤還是配置超限導致的故障。
● OTel × Rust 深度集成:Span 捕捉崩潰
在 Rust 模塊中(如機器人管理模塊),通過 OpenTelemetry Tracing API 植入關鍵 Span,當程序執行到異常分支時,崩潰堆棧、錯誤路徑、線程 panic 信息,都會原樣記錄到鏈路中。
03
直擊異常堆棧:捕獲 Rust panic 根因
OpenTelemetry Logging 會把 crash 信息直接寫入對應的 Trace 中,形成“證據鏈”。
例如 Cloudflare 事故中的關鍵信息:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
這條信息的意義非常明確:
程序并未遭遇外部攻擊、崩潰的根因是 Rust 代碼對異常數據使用了 unwrap() 強制解包、核心代理線程因此 panic,觸發 5xx 洪峰、整個問題是內部配置數據異常導致而非 DDoS。這種基于鏈路與堆棧的“可證據化判斷”,能讓團隊在數分鐘內鎖定故障點,避免方向性錯誤。
04
優化策略:APM 的“診斷悖論”與動態采樣
根據復盤信息,在受影響期間,CDN 的響應延遲顯著增加。這是因為 Cloudflare 調試和可觀測系統消耗了大量 CPU 資源,這些系統會自動為未處理的錯誤添加額外的調試信息。
這種現象揭示了 APM 在大規模故障時的“診斷悖論”:為了獲取故障的詳細信息,診斷工具本身的資源消耗反而可能加劇服務的性能問題(延遲增加)。
APM 必須采取以下策略,以實現可觀測性與資源消耗之間的平衡:
● 實施錯誤報告節流與資源預算限制
目標: 防止核心轉儲或其他錯誤報告占用過多系統資源。
當系統遭遇大規模、高頻率的錯誤(例如 5xx 錯誤數量激增)時,APM 系統必須具備自我保護機制,以確保診斷工具本身不會成為瓶頸。
? 資源預算限制: APM 代理應設置嚴格的 CPU 和 I/O 預算限制。一旦核心代理(如 FL2)的錯誤率達到臨界閾值,APM 系統應立即啟動節流機制。
? 信息詳細程度降級: 避免生成資源密集型的完整核心轉儲。相反,APM 應降級為只收集關鍵的、輕量級的信息,例如:只記錄導致線程崩潰的 異常堆棧信息(如 panic),并對重復發生的高頻錯誤進行聚合和采樣,以降低整體數據處理負荷。
● 采用動態自適應采樣 (Adaptive Sampling)
目標: 將有限的診斷資源集中于最有價值的故障數據,避免為正常流量或低價值的重復錯誤浪費 CPU。
? 狀態驅動的優先級: 當 APM 檢測到 5xx 錯誤 HTTP 狀態代碼的數量急劇增加 時,系統應從常規的隨機采樣切換為基于錯誤的優先級采樣。
? 實施細節:
在可觀測性與APM系統中,數據采集的深度與資源消耗直接相關。為在確保故障可診斷性的同時避免自身成為性能瓶頸,可采用以下采樣或熔斷策略:
● 探針熔斷:系統可根據實時資源使用情況,自動調整采樣策略與資源分配,實現觀測力度與系統開銷之間的平衡,確保業務性能不受觀測活動影響。
● 對故障請求全量追蹤:針對所有導致5xx錯誤的請求,執行100%全量采集,完整記錄分布式鏈路與異常堆棧,確保在關鍵故障場景下不丟失診斷所需的核心信息。
● 對正常請求降低采樣:在系統異常期間,對仍能成功返回的請求(如200 OK)大幅降低采樣率。此舉可顯著節省CPU、內存與帶寬資源,減輕系統整體負載,避免因觀測開銷加劇業務延遲。
相反,對于在故障時段仍成功運行且快速響應的請求(如 200 OK),則應大幅降低其采樣率,從而釋放出 CPU 資源,減輕系統整體負載,避免調試和可觀測系統本身消耗大量 CPU 資源,進而加劇 CDN 響應延遲。
通過這些策略,APM 能夠確保在服務中斷的最關鍵時刻,將 CPU 資源集中用于捕獲 定位根源(例如,panic 和特征文件體積異常) 所必需的精確數據,同時避免因過度調試導致系統二次崩潰或延遲增加。這種優化是 “防止核心轉儲或其他錯誤報告占用過多系統資源” 這一后續步驟的直接落地。
從告警到攻擊鏈
構建更清晰、更安靜的安全體系
Cloudflare 級別的故障表明,在復雜、多依賴的現代系統中,真正的挑戰在于對異常本質的理解能力。通過整合用戶側感知(RUM)、網絡層洞察(Network)、應用層診斷(APM)與安全側智能研判(安云),企業能夠構建一個基于全域可觀測性的韌性系統。這套體系的核心價值在于:不僅能在大規模故障中快速定位并恢復,更能從根本上減少誤判、保持“安靜的準確性”,實現從被動響應到主動韌性的轉變。
在未來更復雜的數字環境中,安全和運維不可分割,只有將安全能力融入到全域可觀測的運維體系中,才能真正實現系統的韌性與穩定。理解本質,遠比捕捉表象更重要。
轉自:中國財富網


【版權及免責聲明】凡本網所屬版權作品,轉載時須獲得授權并注明來源“中國產業經濟信息網”,違者本網將保留追究其相關法律責任的權力。凡轉載文章及企業宣傳資訊,僅代表作者個人觀點,不代表本網觀點和立場。版權事宜請聯系:010-65363056。
延伸閱讀


 科技賦能玫瑰產業升級 校企合作共筑鄉村振興新篇章
科技賦能玫瑰產業升級 校企合作共筑鄉村振興新篇章
