4月24日至26日,第三十屆中國醫院信息網絡大會(CHIMA 2026)在珠海舉行。今年的 CHIMA 大會,“智能化”成為貫穿全場的關鍵詞。大會回顧了 CHIMA 三十年的發展歷程,以及中國醫療信息化半個多世紀的演進路徑,并明確指出:醫療行業正在進入一個以數據與智能為核心驅動的新階段。
無論是主論壇還是分論壇分享,AI 在醫療場景中的應用正加速落地——從輔助診療、臨床決策支持,到運營效率優化與患者服務體驗提升,智能化能力正在不斷滲透進醫療業務的核心環節。
與此同時,另一條同樣重要的主線也在持續推進:國產化替代。
當“智能化發展”與“國產化推進”在同一時間窗口疊加,一個更具現實意義的問題開始顯現:現有的數據底座,能否同時承載合規替換與智能升級?

兩個趨勢疊加下的數據底座的挑戰
從實踐來看,不少醫療機構在推進國產化過程中,更多是以“系統替換”為導向,優先滿足合規與安全要求。但在實際落地中,醫院在國產化過程中普遍遇到三類瓶頸:
性能與擴展不足:高并發場景卡頓,復雜查詢跑不動
架構單一:以 TP 事務為主,難以支撐實時分析(AP)與 AI 數據處理
系統割裂:多庫多廠商,數據不通、運維復雜、成本高,數據治理開展難
當AI應用逐步深入,這些問題會被進一步放大。AI 不僅需要數據,更需要高質量、實時、可統一調度的數據能力。
換句話說,如果數據底座不升級,那么無論是國產化,還是智能化,都很難真正釋放價值。
從“能用”到“好用且面向未來”
在這樣的背景下,越來越多行業實踐開始指向一個共識:
數據庫選型,不應只是“是否國產”,更應關注“是否面向未來”。
面向未來的數據底座,需要具備幾個關鍵特征:
統一能力:能夠同時支撐事務處理(TP)、分析處理(AP)以及AI相關負載
彈性擴展:應對醫療場景中突發性增長與不確定性需求
架構演進能力:避免頻繁系統重構帶來的業務風險與成本
開放與兼容:降低遷移門檻,保護既有投入
這種從“單一能力優化”走向“統一架構承載”的變化,本質上是從傳統數據庫向 HTAP(混合事務與分析處理)+ AI 數據底座的演進。
實踐案例:平凱數據庫在江蘇省人民醫院的應用
在本次大會現場,江蘇省人民醫院信息處景慎旗主任分享了醫院在數據底座與智能化應用方面的實踐路徑。

景慎旗主任介紹,醫院早在 2018 年數據中心升級過程中,便引入國產分布式數據庫——平凱數據庫(TiDB 企業版),逐步承載核心業務系統運行。在此基礎上,圍繞未來智能化需求,構建了“多模態、多中心、多場景”的數據體系:不僅整合文本、影像、視頻等多源數據,還實現了多院區數據融合與科研、臨床等多場景貫通。
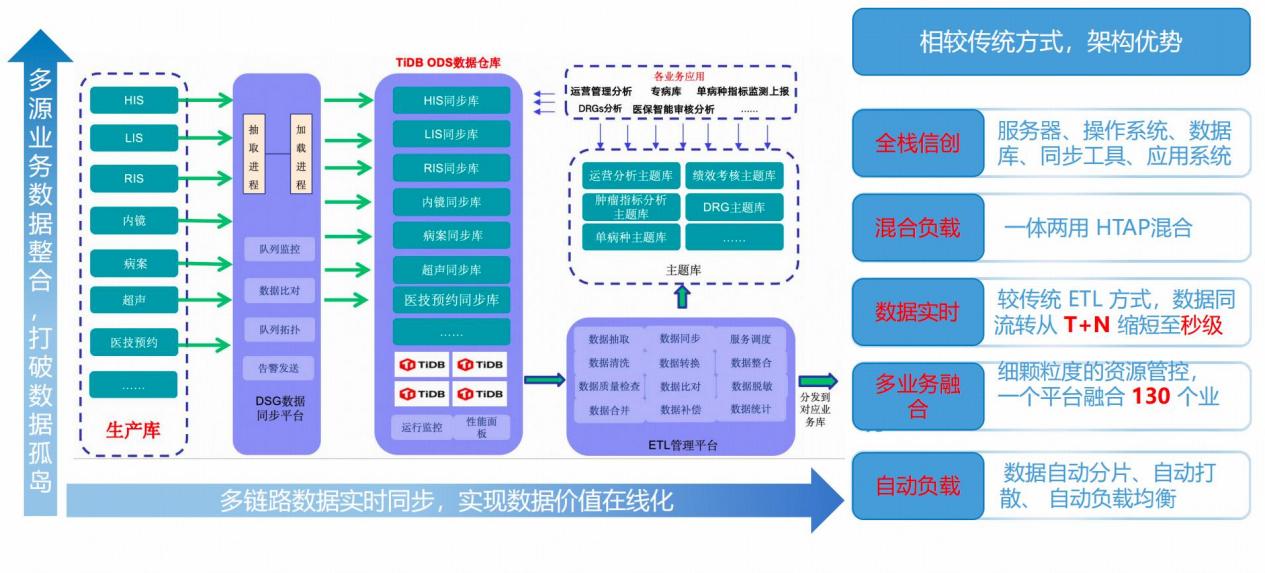
在應用層面,人工智能正加速落地。包括重癥監護大模型對患者指標的實時分析、影像與病理的智能輔助診斷,以及檢驗報告自動解讀等,均已進入實際應用或試點階段。
“高質量數據是人工智能的燃料”,景慎旗表示,“數據中心建設的核心,是為智能化提供持續支撐。”
國產化與智能化,不應是“取舍題”
在國產化與智能化并行發展的背景下,醫療行業該如何選擇數據庫?
答案并不在于“選擇哪一方”,而在于是否能夠找到一個同時支撐兩者的基礎架構。
以新一代分布式數據庫為代表的技術路線,正在提供一種新的可能: 在滿足國產化要求的同時,通過統一的 TP+AP+AI 能力,為未來智能應用預留空間。平凱數據庫(TiDB 企業版)以分布式架構為基礎,在滿足信創合規要求的同時,提供:
一庫承載多系統,消除數據孤島
HTAP 混合負載,支撐實時分析與 AI
彈性擴展,適配多院區與流量波動
簡化架構、顯著降低許可與運維成本
該架構已在互聯網、AI、金融科技場景大規模驗證,能夠支撐大模型、Agent、實時監控、數據中臺等高要求場景。
例如:
某家頂級 Agent 公司,該公司多 Agent 系統在短時間內迎來爆發式增長。面對流量與計算需求的劇烈波動,其背后的數據底座依托極致彈性與 Scale-to-Zero 能力,實現秒級擴縮容,在資源“隨用隨起、用完即停”的同時,穩穩承載了數天內的業務激增。
開源大模型應用平臺 Dify 也在其數據底座中引入分布式數據庫,用于承載多租戶環境下的向量數據、應用狀態與實時交互數據,支撐智能體與大模型應用的快速構建與迭代。
從這些實踐可以看到,當業務走向高并發、實時化與智能化,數據底座往往需要同時具備事務處理、分析處理以及 AI 數據支撐能力。這也進一步印證了:數據庫架構的演進,正在成為支撐新一代應用形態的關鍵基礎。
結語:面向未來的底座,決定上限
醫療行業正站在一個關鍵節點。
一方面,是國產化帶來的基礎設施重構;
另一方面,是智能化帶來的應用創新浪潮。
在這兩股力量交匯之處,數據庫不再只是“支撐系統運行的組件”,而正在成為決定數據價值上限的關鍵基礎設施。
一個正在被行業認真面對的問題是:
在下一輪醫療信息化升級中,我們選擇的是“完成替代與遷移”,還是構建一個真正面向未來、能夠持續承載智能化演進的數據底座?

轉自:鷹潭新聞網


【版權及免責聲明】凡本網所屬版權作品,轉載時須獲得授權并注明來源“中國產業經濟信息網”,違者本網將保留追究其相關法律責任的權力。凡轉載文章及企業宣傳資訊,僅代表作者個人觀點,不代表本網觀點和立場。版權事宜請聯系:010-65363056。
延伸閱讀



